序列化方法综述
前言
序列化,顾名思义,是把一个非线性排布的数据用线性顺序来表示。
为什么需要序列化?因为当一个数据需要进行 传输 或者进行 持久存储 时,都必须变成能用 0 1 表示的、有顺序的 的数据。
从更底层来看,不同机器间传输数据终究会变成电信号,现在通用的串口方案中,一个时钟周期仅能传输一个 bit 的数据,并且有且仅有一个通道,所以要传输的数据本身就得符合这个特征。
【补图,串口通信时的过程】
当一个数据在内存中时,由编程语言维护变量在内存中的排布规则,有可能是顺序的,也有可能是内存引用。 当我们希望把一个在内存中可能分散排布的数据存到磁盘上时,就必须满足文件系统的特征,而文件系统,就是被抽象成了一个有大小的条带状的存储空间。
【补图,数据的内存状态,文件系统的抽象表示】
前面说得比较抽象,其实从实践理解起来很简单,以 js 中的一个 Object 为例:
1 | |
这就是最简单的序列化格式: JSON
文本格式与二进制格式
文本格式
从 IT 诞生之初,人们就在处理如何存储数据的问题了。最简单的数据存储格式,就是文本格式,这也是人最容易理解的格式。
文本格式,也就是把数据用文本进行表示(编码格式可能是 ASCII,也可能是 UTF8 等等),用一些特定的符号作为分隔,比如常用的有 换行符 \n 制表符 \t 逗号 , 等等。最好的例子就是 csv 格式 (Comma-Separated Values),一个例子如下:
1 | |
这就是用换行符作为一行数据的分隔,用逗号作为一个字段数据的分隔,在文件中是以文本格式进行编码存储的,在磁盘上的存储内容如下: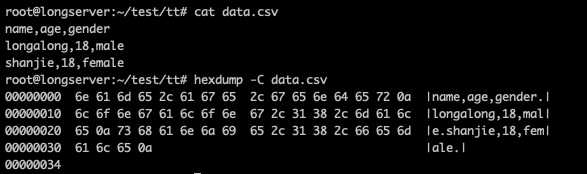
CSV 是表格数据存储时常用的格式,因为非常简单,还能追加写入,数据的空间占比非常高 (因为仅有 逗号 和 换行符 是非数据部分)。
CSV 还有一个变体,用 制表符 \t 代替 逗号 ,,叫做 TSV (Tab-Separated Values),这个格式在一些数据库导入导出数据时会用到,相比于 csv ,主要的优势在于 逗号可能是文本的一部分而容易出错 (当然,可以使用双引号把文本括起来解决)。
对于非表格结构的数据格式,用 CSV 就不太好表示了,取而代之的是 json 、yaml、ini、xml 等等,值得一提的是, excel文件 本质也是一个有特定字段的 xml 文本文件,对一个 excel 文件解压后,就能看到数据表的实际表示方式了。
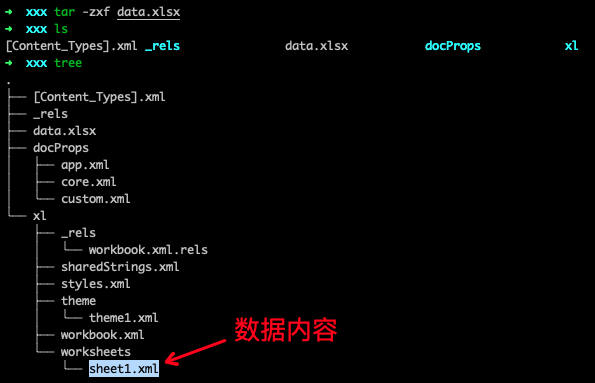
上面同样的例子用 json 表示后,在磁盘上的结构如下: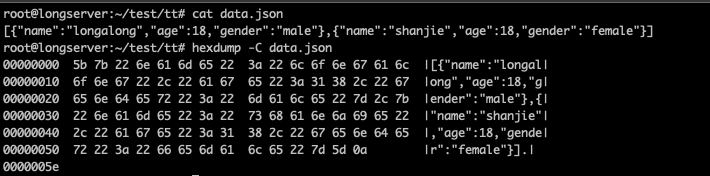
二进制格式
文本格式因其简单、对人友好而被广泛应用,但文本格式也有其不足之处,其中有两个主要的问题: 1. 分隔符用文本表示占用较多空间,降低了数据的密度 2. 文本格式数据在序列化和反序列化时的成本更高。
对于简单的场景,数据量级很小,考虑到调试的方便性,文本格式是很不错的选择。如果数据量级很大,又需要频繁进行序列化和反序列化的操作时,磁盘空间 和 cpu耗用 的考虑优先级会大于方便性,因此往往会采用二进制的格式。
根据场景的不同,二进制格式的数据表示方式也有所不同。整体我们可以分为两种类型:特定语言实现的序列化方法、通用语言的序列化方法。
很多高级语言都有自己特定的序列化方法,便于开发者直接把内存中的一些数据存储到磁盘上,常见的有: python 的 pickle 、java 的 java.io.Serializable、 golang 的 gob 。 这部分内容可以在 语言限定的序列化方法 中了解更多。
通用语言的序列化方法,通常提供多种语言的 sdk 实现,以便实现跨语言数据操作。常见的跨语言序列化方法有:protobuf、hession、thrift、avro、flatbuffer、msgpack 、bson 等等。
不同的二进制序列化方法针对不同的场景进行了优化,所以其特点也有所不同,有些是为了降低存储数据量,让数据更加紧密,有些是为了序列化更快等等。可以在 二进制序列化比较 中了解更多。
【补图,一个 pb 的存储、一个 bson 的存储】
序列化要考虑的因素
序列化作为一个传输和存储过程必定会发生的环节,可以从 序列化性能、数据块大小、反序列化性能、安全性、语言支持、易用性、可维护性(兼容性) 这些角度来考虑,具体的选择还需要根据实际场景而定。
Don’t cry because it’s over. Smile because it happened.
— Dr. Seuss
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!