二进制序列化比较
前言
上一节 JSON及其相关变体 中,我们对文本格式的序列化方法做了梳理,也对类 json 的另外两种二进制序列化方法 bson 和 msgpack 做了拆解。从「是否有 schema」的维度,我们可以将上一节定义为 schema-less 的序列化方法,而本节中,则是有 schema 的三种二进制序列化方法的探索。
schema 之争
所谓有 schema,即「数据有明确的类型和格式要求」,而 schema-less 则对应为 「无明确的类型和格式要求」或者我们常用另一种说法「自描述」。
对于一个可嵌套的多类型数据,自描述需要对以下 3 个方面进行描述:
- 字段含义
- 字段类型
- 字段间的分隔
json 就是一种典型的自描述数据格式,如下的 json 中,每一个字段(field)都有一个 key 和一个 value,其中 key 就是对这个字段的含义描述;其中 name 对应的 value "longalong" 是一个用引号包起来的内容,这里的引号,就是对字段类型的描述;每个字段结尾处的 逗号 , 则是对字段间的分隔。 json 就是用这三种方式实现了自描述的能力。
1 | |
自描述带来的价值,是使得一个数据可以独立地被使用,使用方能够根据自己的需要解析出数值。但这也带来了另一个问题: 数据的信息密度更低了! 上面的这个例子中,真正有价值的信息只有 longalong、18、cooking、eating 这几项,本身仅占 24 个字符,但其他数据却占了 36 个字符,也就意味着这样一个 json 字符串的有效信息占比仅为 24 / (24 + 36) = 40% 。
这样低效的信息占比,在常规的接口请求场景还能接受,但在一些对「性能」或者「存储量」有要求的场景中就很低了,比如 数据库 和 rpc。
优化的方向也很清晰:对于特定的数据结构,把共性的描述部分提取出来,以更轻量的指代方式替之。这也就是提取 schema 的方法。
提取 schema 方案的序列化方法很多,我们选择其中最具代表性的 3 个做进一步分析:
- protocol buffer
- flatbuffer
- thrift
schema 的兼容性问题
在开始具体分析上述的每一个序列化方法之前,我们先来探讨 schema 引入的一个问题 —— 兼容性。
schema 是针对一个特定数据格式的描述,在我们日常开发时,schema 的变动是一定会发生的。如果不处理好 schema 变更的兼容问题,就会出现意想不到的事故,血泪教训。
eg: 😁 比如用 gender 表示性别,原本我们使用一个 bit,0 表示 female,1 表示 male,但后来发现有些动物可能存在另外的状态,比如 无性 或者 雌雄同体,那原本的 schema 就会发生变动。
兼容的模式可以分为:
- 向前兼容 (新代码能够处理老版本数据)
- 向后兼容 (老代码能够忽略新版本数据)
为了避免 schema 变动产生事故,业界主要有如下几种思路:
- 业务代码兼容
- 类型变化的兼容 (oneof)
- 实现向前兼容
- 实现向后兼容
- schema规范
- 不允许类型改变,使用新增 field 的方式实现
- 其他可参考 protobuf 的 guide
- 提供 schema 转换功能 (例如 k8s 的 crd)
protobuf 的方案
我们看一个方案,一般会从这些方面去关注:
- 协议设计 (底层能力)
- 实现方案 (比如编码方法)
- 相关生态
- 特征及适用性
- 使用案例 (怎么用、最佳实践)
在序列化方案中,对应需要关注这些:
- 协议设计
- 协议表示方法 (proto 文档)
- 结构体表示方法 (message)
- api 表示方法 (service)
- 类型系统 (基本类型、message)
- 兼容性
- 扩展机制 (plugin)
- 调试能力
- 实现方案
- proto 解析实现 (C++ 的 protoc)
- 编码实现方法 (var int、constant int、string/bytes、struct/map/array)
- 语言实现 (golang sdk)
- 跨语言兼容性
- 扩展机制的实现方法 (eg: go-kratos 中)
- 相关生态
- 工具链 (vscode prompt、protoc……)
- 各语言 sdk
- rpc 框架使用情况 (grpc)
proto3
一定要注意,proto2 和 proto3 之前的差别非常大,而且不兼容,相比于 proto2 ,proto3 取消了 optional、required 和 default 关键字,因此在这些功能点上弱于 proto2,若有这些功能需求的话(尤其是 default),就需要调研清楚了。
编码格式
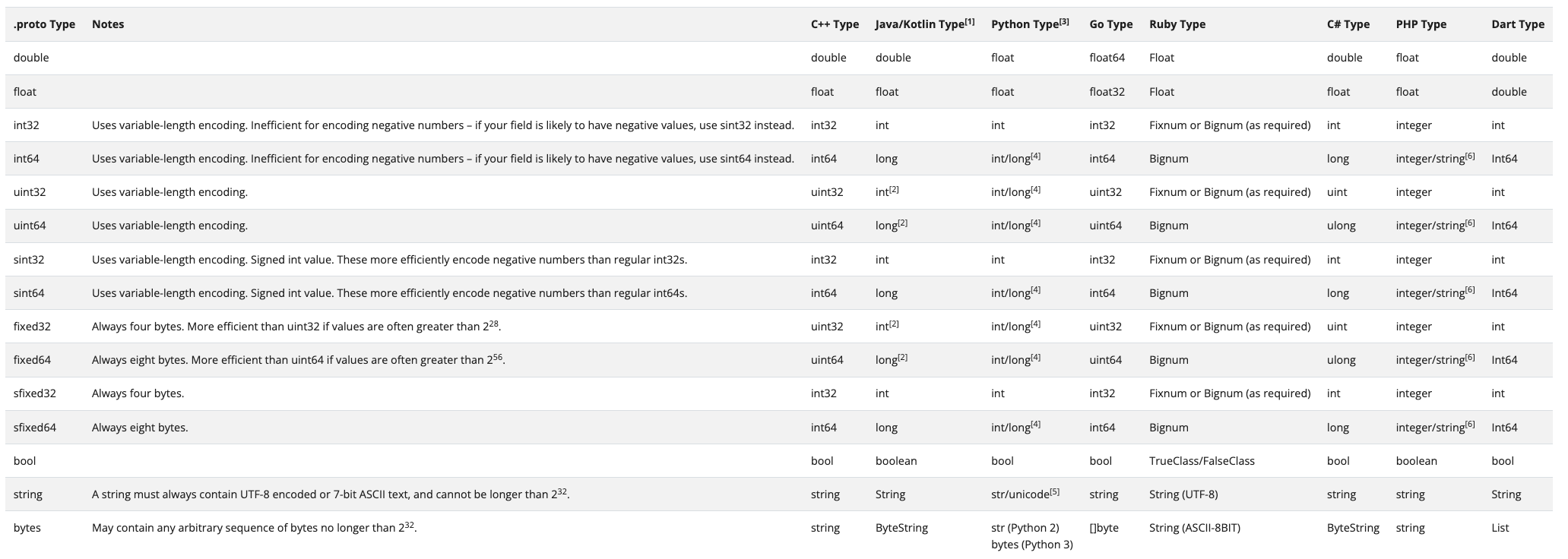
从模式上,编码分为两种类型:
- 定长数据类型: 类型 + 值
- 变长数据类型: 类型 + 长度 + 值
从编码优化的方式上,protobuf 采用了多个方案,主要如下:
- int 采用了 varint 的编码压缩 (实现在
encoding/protowire/wire.go:AppendVarint) - int 负数采用了 zigzag 进行编码压缩 (实现在
encoding/protowire/wire.go:EncodeZigZag)
可参考文章:
https://www.zbpblog.com/blog-397.html
https://www.sobyte.net/post/2022-03/pb-encoding/
https://en.wikipedia.org/wiki/LEB128
https://en.wikipedia.org/wiki/Comparison_of_data-serialization_formats
一个简单的例子
我们假设 proto 如下:
1 | |
代码如下:
1 | |
运行上面的代码,得到的结果如下:
- 第 1 个 byte
00001000的含义是: 前 5 位00001代表 tag 编码为 1,000代表 varint。 - 第 2 个 byte
00010010的含义是: 整数 18。 - 第 3 个 byte
00010010的含义是: 前 5 位00010代表 tag 编码为 2,010代表 len prefixed。 - 第 4 个 byte
00001001的含义是: varint 编码后的整数 9,意味 tag 为 2 的字段长度为 9 bytes。 - 第 5 - 13 个 bytes 的含义为:tag 为 2 的字段内容,从嗅探的角度可以知道为 “longalong”
- 第 14 个 byte
00011101的含义是: 前 5 位00011代表 tag 编码为 3,101代表 fixed 32。 - 第 15 - 18 个 bytes 的含义为: IEEE 754 编码后的 float 数,解码后为 5.2。
- 第 19 个 byte
00100010的含义是: 前 5 位00100代表 tag 编码为 4,010代表 len prefixed。 - 第 20 个 byte
00001001的含义是:tag 为 4 的字段的长度为 9 bytes。 - 第 21 - 29 个bytes 则为 tag 为 9 的内容,但由于类型为 repeated string,所以内容本身还要做一次解析。
- 第 21 个 byte
00001010的含义是: 前 5 位00001代表 tag 编码为 1,010代表 len prefixed。 - 第 22 个 byte
00000111的含义是: tag 为 1 的字段长度为 7。 - 第 23 - 29 则为 tag 为 1 的字段内容,从嗅探角度可以知道为 “cooking”
- 第 30 个 byte
00100010的含义和第 19 个byte 一样,因为是 repeated 的第二个 item。 - 第 31 - 39 的含义和 21 - 29 一样。
- 第 40 个 byte
00101010的含义是: 前 5 位00101代表 tag 编码为 5,010代表 len prefixed。 - 第 41 个 byte
00001100的含义是: tag 为 5 的字段长度为 12。 - 第 42 - 53 bytes 则为 tag 5 的字段的全内容,但由于是嵌套结构体,因此需要近一步解析。
- 第 42 个 byte
00001000的含义和第一个 byte 含义相同,tag 为 1 的字段类型为 varint。 - 第 43 个 byte
00010001的含义为 tag 为 1 的字段值为 17 - 第 44 - 53 bytes 和 第 3 - 13 bytes 含义相同。
thrift 的方案
thrift 本身是一个庞大体系的 rpc 框架,序列化只是其中的一小部分,二进制序列化方法中有: binary 和 compact 两种。
binary 查看: binary 的 spec
compact 查看: compact 的 spec
实际上,compact 的格式和 pb 非常类似,而 binary 则相当于去掉 varint 和 zigzag 编码压缩。由于没有太核心的差别,就暂时不做实验了。
可以参考的文章:
flatbuffer 的方案
flatbuffer 有一些基本特征如下:
- 支持默认值设置 (但有些语言不支持,比如 golang 无法设置 string 等)
- 不直接支持 map (需要自己用 list 和 item 实现)
- 因为编码是从后往前进行的,所以需要按倒序做数据准备
- struct 和 table 是两个不同的编码方式,struct 是紧凑排布的,table 有 vtable 做索引
- struct 只支持标量,标量不包含 string,详情可参考官方文档 的 Types 部分
- struct 没有不支持多个版本兼容,任意修改都无法做到前后兼容
- 要想向后兼容,vtable 字段不支持修改顺序、不支持删除字段、不支持在中间添加字段。仅有在尾部添加字段时可 老代码 忽略 新数据,新代码 用默认值 兼容老数据。
编码的原理可以参考 binary format
编码的例子解释可以参考 flatbuffer encode
一个简单的例子
例子如下:
1 | |
代码如下:
1 | |
为了辅助观察,打印的 util 如下:
1 | |
运行结果如下:
简单解释一下:
- 1-4 bytes: table 正式开始的偏移量 (意味着第 21 个 byte
00001110是 table 的开始) - 5-6 bytes: 全局 4 bytes 的对齐补充 (不一定会有)
- 7-8 bytes:
00001110 00000000当前 vtable 的长度为 14 - 9-10 bytes:
00100000 00000000对应的 table 的长度为 32 - 11-12 bytes:
00010100 00000000第一个字段内容在 table 的第 20 位之后开始 (name) - 13-14 bytes:
00011100 00000000第二个字段在 table 的第 28 位之后开始 (nickname) - 15-16 bytes:
00011000 00000000第三个字段在 table 的第 24 位之后开始 (age) - 17-18 bytes:
00001100 00000000第四个字段在 table 的第 12 位之后开始 (base_info) - 19-20 bytes:
00000100 00000000第五个字段在 table 的第 4 位之后开始 (hobbies)
21 bytes 开始则是 table 部分
- 21-24 btyes:
00001110 00000000 00000000 00000000table 对应的 vtable 的位置,表示往前 14 bytes 就是 vtable 的开始,即第 7 个 byte。 - 25-28 bytes:
00111000 00000000 00000000 00000000这是 hobbies 字段的第一个值,由于 hobby 是 string,因此表示从当前偏移 56 byte 就能拿到 string 内容,即第 81 byte 开始。 - 29-32 bytes:
01000000 00000000 00000000 00000000同上,表示从当前偏移 64 byte 即可拿到 string 内容,即第 93 byte 开始。 - 33-36 bytes:
10101111 00000000 00000000 00000000为 base_info 的第一个字段,由于 base_info 是 struct,因此值本身就代表 struct 的第一个字段 height,值为 175。 - 37-40 bytes:
00000000 00000000 10010001 01000010同上,为第二个字段,值为 72.5。 - 41-44 bytes:
00011000 00000000 00000000 00000000由于 name 是 string,因此这代表 name 值的位置在当前偏移 24,即第 65 个 byte 开始。 - 45-48 bytes:
00010010 00000000 00000000 00000000由于 age 为 int32,因此直接为值内容 18。 - 49-52 bytes:
00000100 00000000 00000000 00000000由于 nick name 为 string,这代表值在当前偏移 4 的位置,即第 53 byte开始。 - 53-56 bytes:
00000110 00000000 00000000 00000000表示 nick name 的 string 长度,为 6 bytes。 - 57-63 bytes: 为 nick name 内容 “kuhaha”,长度为 6,同时 string 要补一个
0(我也没搞懂为啥要补,感觉可以不用) - 64 bytes: 由于 nick name 总共占了 7 bytes,但根据内存对齐要求,需要到达 4 bytes 的倍数,因此补一个
0 - 65-80 bytes: name 对应的字符串 “longalong”
- 81-92 bytes: hobbies 的第一个 item 对应的字符串 “eating”
- 93-104 bytes: hobbies 的第一个 item 对应的字符串 “cooking”
特征及适用场景分析
我们从 数据大小、编解码速度、原地修改、兼容性、可调试性 的角度对 fb 和 pb 做一个比较。
数据大小:
- fb: 由于存在大量的 offset,且每一个 int 都没做压缩,因此编码后的很大,上面的例子中,有效数据为 “longalong” “longsir” “eating” “cooking” “18” “175” “72.5”,数据大小仅为 41 bytes,但实际占用 104 bytes,有效比仅有 39.4%
- pb: 由于采用了 varint 编码,int 数据在值较小时占用很低,上面的例子中,有效数据大小为 42 bytes,实际占用 53 bytes,有效比达到了 79.2%
编码速度:
- fb: 由于从后往前编码,需要大量 copy 操作、需要多次计算 offset 等,编码效率较低。
- pb: 大多数情况编码效率较高,但也有 varint 压缩会拉低编码速度。
解码速度:
- fb: 由于所有读取均有 offset 索引,所以可以非常快速读取。
- pb: 解码时需要做较多的 varint 解析,速度逊色与 fb。
这是 fb 官方做的 C++ 的性能对比: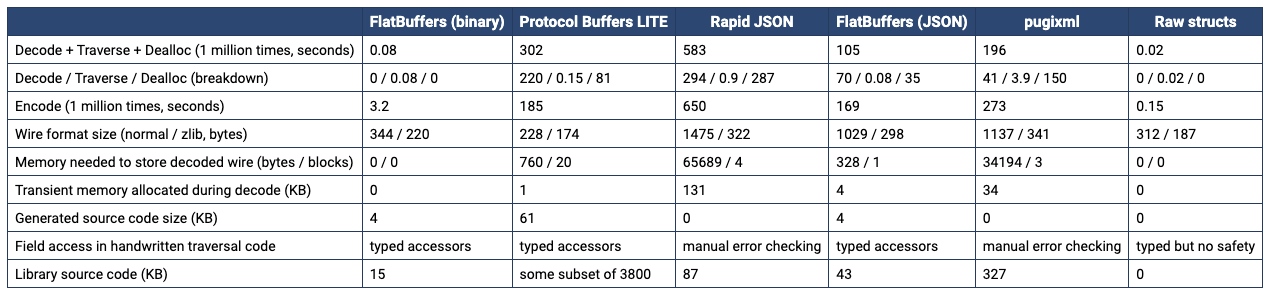
原地修改:
- fb: 对于标量数据,可以在编译时指定参数以实现原地修改。非标量不可原地修改。(但 go sdk 还未实现)
- pb: 不支持。但从逻辑上讲,fixed32 和 fixed64 是能够实现原地修改的。
跨语言兼容性:
- fb: 兼容绝大多数流行的编程语言。但从实现来看,比如 default 能力并非各语言实现一致。
- pb: 兼容绝大多数流行的编程语言。
多版本兼容性:
- fb: 由于 vtable 和 struct 都是基于顺序的定位方式,所以对字段的增删不是很友好。
- pb: 由于使用 tag 作为定位方式,只要 tag 不重复使用,对字段增删操作较友好。
可调试性:
- fb: 无。
- pb: 可用 jsonpb、textpb 等格式,便于肉眼查看。
对于更多的比较,强烈推荐阅读 Comparison of data-serialization formats 这篇 wiki。
特别探索–pb的反向工程
从模式上看,是可以通过嗅探的方式反向推导 pb 的类型和值对应关系,最后得到的是一个满足条件的 k-v 对应关系,例如一个 json,只是 json 的 key 是 1、2、3 这类 tag。
【之后空了可以写个小工具】
特别探索–编码过程可视化
只要理解了编码的过程,也基本就能理解各种序列化方案的原理和特征。
受一些编程类游戏的启发,若能把编码过程可视化了,则大家理解序列化就更加简单了。
不仅编码过程可以可视化,更有挑战一点的,可以把一些数据库的存取流程可视化了。
就像有人把排序算法可视化一样,学习效果必定非常好。
【之后空了可以探索一下】
proto2 和 proto3 的比较
由于 proto2 和 proto3 有很大的改变,尤其是在 默认值 这项能力上,因此一些场景下也可能仅可使用 proto2 。
【之后空了可以探索一下】
He who learns must suffer. And even in our sleep pain that cannot forget falls drop by drop upon the heart, and in our own despair, against our will, comes wisdom to us by the awful grace of God.
— Aeschylus
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!