记一次服务性能的调优排查
事情起因:
某一天,听到浩兄说我们有个告警,是因为 event-tracking 的 cpu 使用超标

我感觉比较奇怪,顺口问了下情况,后来又和 浩兄、窦兄 一起看了下各种监控
查看 cpu、内存、网络 情况
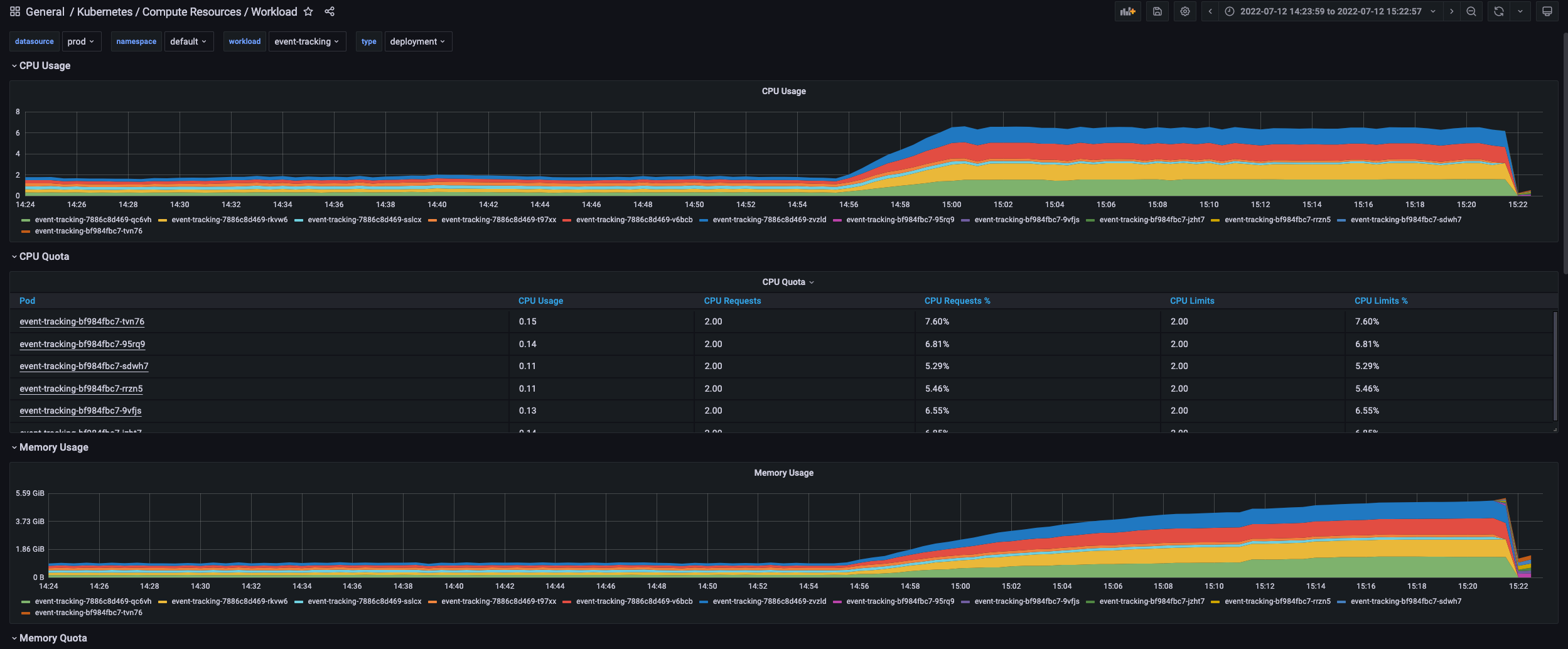
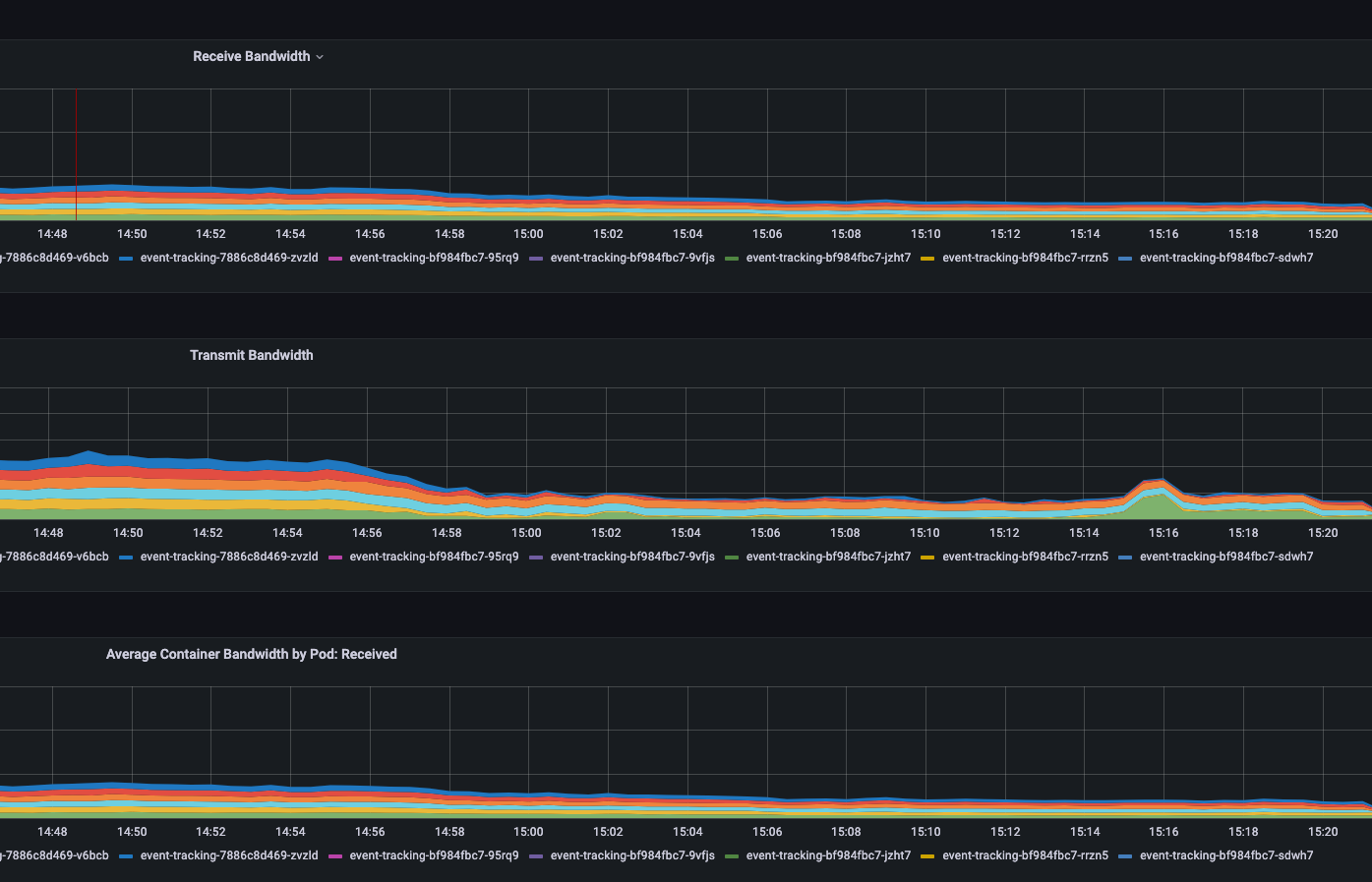
发现很奇怪,内存和 cpu 是猛增上去的,但网络流量却非常小。
又听到 浩兄 说当时机器的 socket 连接数被打满了,于是怀疑是 goroutine 的问题,进一步查看 goroutine 监控
查看 goroutine 监控
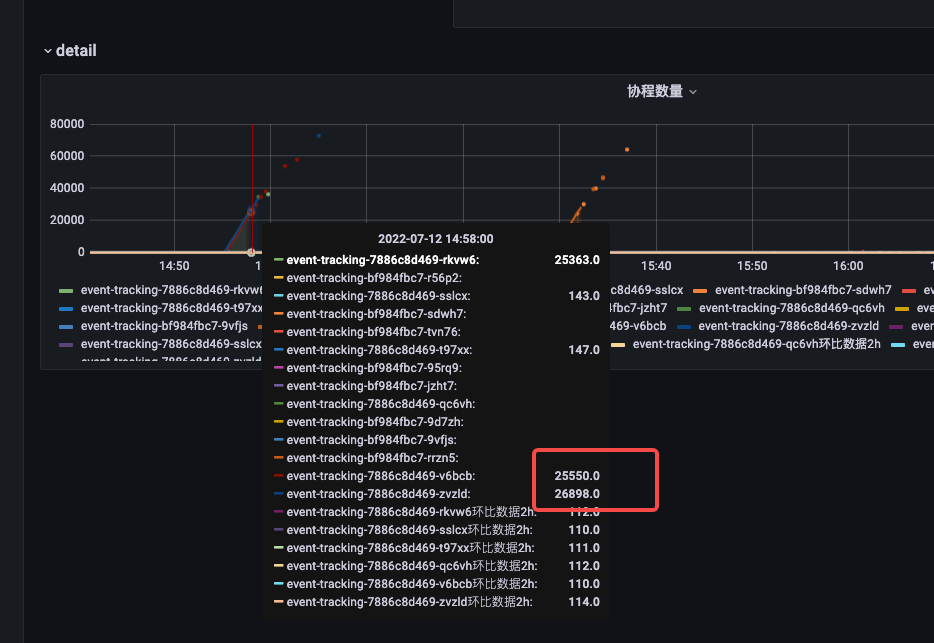
发现确实 goroutine 飙得非常高。 也没多想,怀疑是不是有 for 循环里面起了 协程,导致 goroutine 没控制住?
于是和 窦兄 一块儿,一通代码查看,……额……,没发现啥问题。
此事一直耿耿于怀,听相关负责人说,在计划重构 event-tracking ,有点害怕,毕竟私有部署的项目中,我还有些依赖 event-tracking 的 sdk [😱]……
但由于 ① 没有现场,没法抓各种 profile ② 没有 tracing,不知道究竟卡在哪里了
毕竟,日志、监控、tracing、pprof 相当于我们的眼睛,没有这些,现在做一切都相当于盲猜……
为了减轻私有化适配的工作,在浩兄的怂恿下,开始了一番自救操作……
进一步排查的准备工作
由于不知道各接口的响应情况,于是初步建了个 metrics 的板子,简单看了下,觉得挖不同接口的响应时长可能没啥意义,这应该是个系统性问题,于是放弃继续做板子,转向其他方向。
由于已经在框架中集成了 tracing 的东西,于是花了半个小时把 event-tracking 的 所有 tracing 接上。(包括 redis、db、kafka、http request)
为了能复现高压力下的场景,在压测机上装了 ab
试下未做调整时的压测情况
压测结果
并发 200, qps 54


tracing
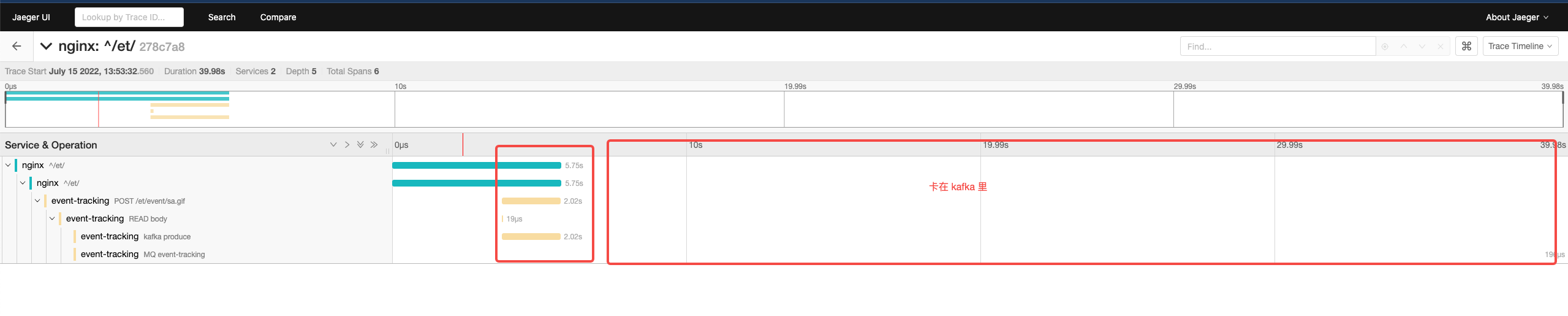
有四个表现奇怪的地方:
负载非常不均衡,必定有鬼
nginx 到 pod 的时间居然达到数秒
Pod 内 produce kafka 的时间 居然和 整个请求的时长一样
在 kafka 队列中,居然卡了这么长时间
先怀疑下 kafka 实例的问题
kafka 监控
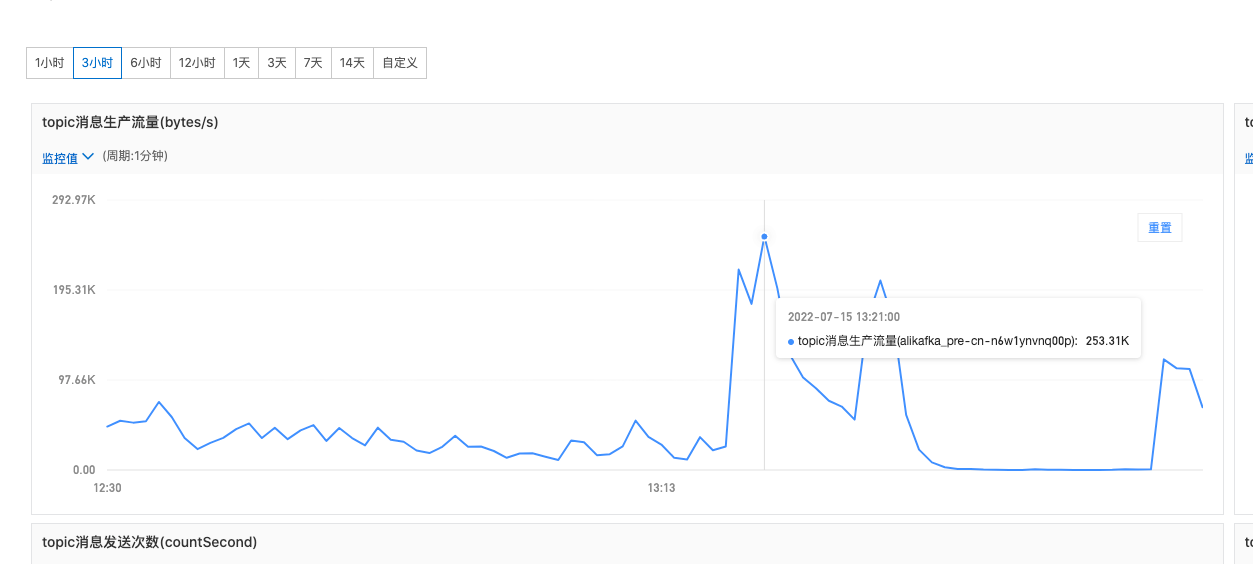
就这点量,远远达不到 kafka 的瓶颈,跳过。
怀疑下 是不是代码中用了 同步发送
看来并不是,排除。
怀疑一下 ikafka 包的问题
此时发现 ikafka 没有接 metrics ,于是看了下之前写的文档,想把 ikafka 的 metrics 接上。
然后发现 我想接的是 sarama ,但 ikafka 没有暴露 metrics 出来,也没有把 sarama 的 metrics 接口暴露出来,无果……
这个问题留到之后再怀疑吧
怀疑一下 kafka 的配置问题
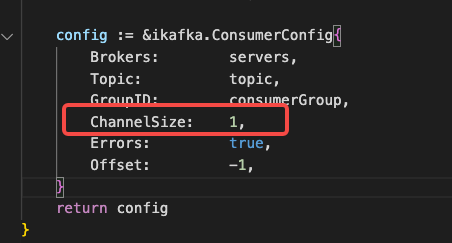
果然,看到了一个问题,consumer 的 队列数 居然仅设置了 1 ,这岂不是意味着,消息只能一条条从 kafka 取回来?那不得老慢了……
另外,看到没有开 autocommit,于是也顺手加上。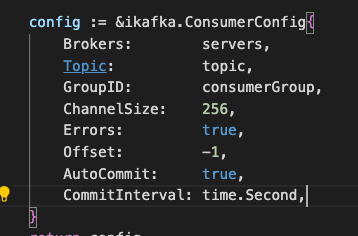
ok,这下顺眼多了。其他也不知道咋样,先压一波试下吧。
调整 channel size 后的压测
刚准备压的,看了一眼 grafana ,懵了……
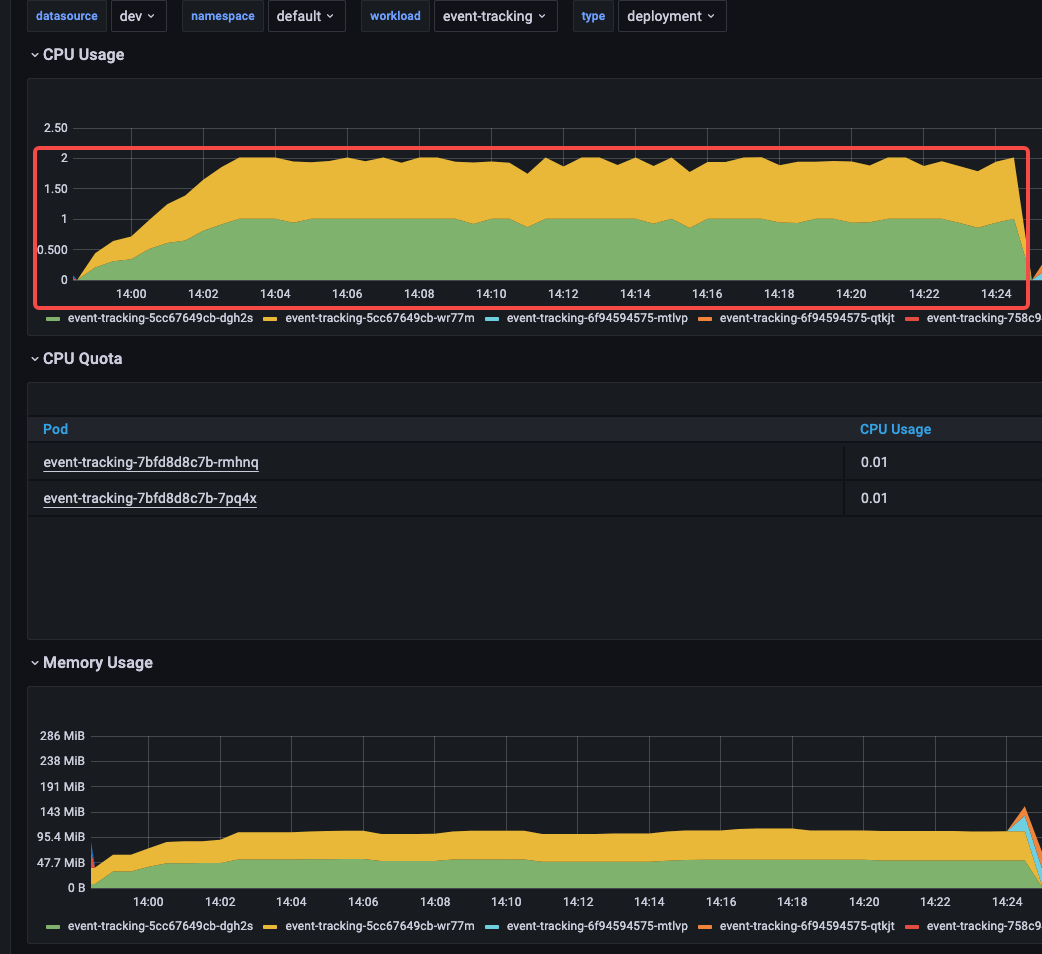
啥情况??? Cpu 直接被拉满了???
吓得我反手就抓了一波 pprofile
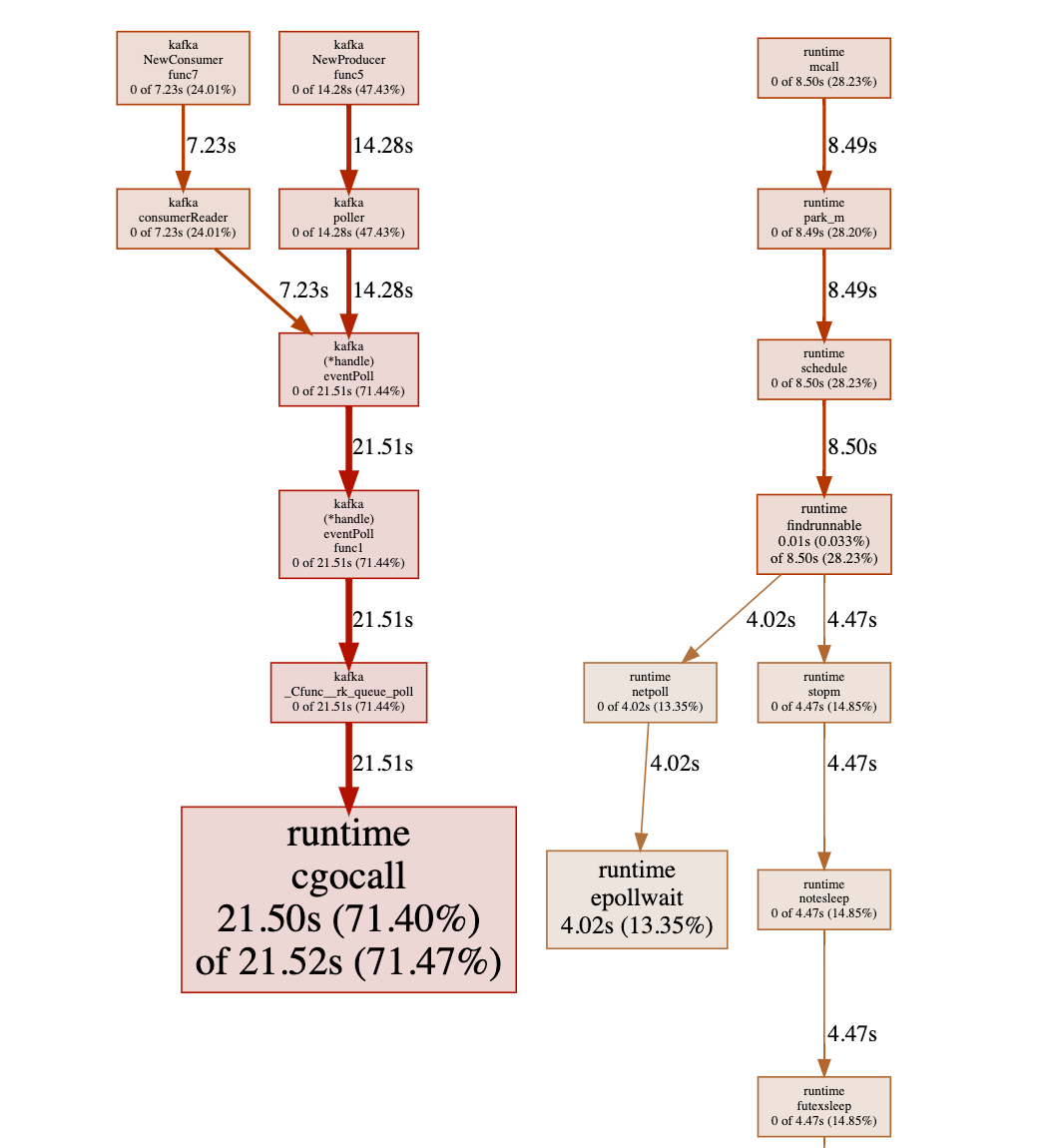
发现居然有大量的 park 方法的调用,这显然就是 goroutine 疯狂切换导致的问题啊。
按以往的经验,很有可能是 for 循环中的 select 不是全阻塞的。此时跑去搜了一圈 for 的代码。没发现问题,每个 for 循环都还比较规范……
于是回来接着看 pprofile,注意到 左边 kafka 的调用,按理,这是属于底层包的调用啊,应该不会有啥问题啊。
跟了一圈代码,由于是直接的 cgo 调用,也很难继续追下去了。
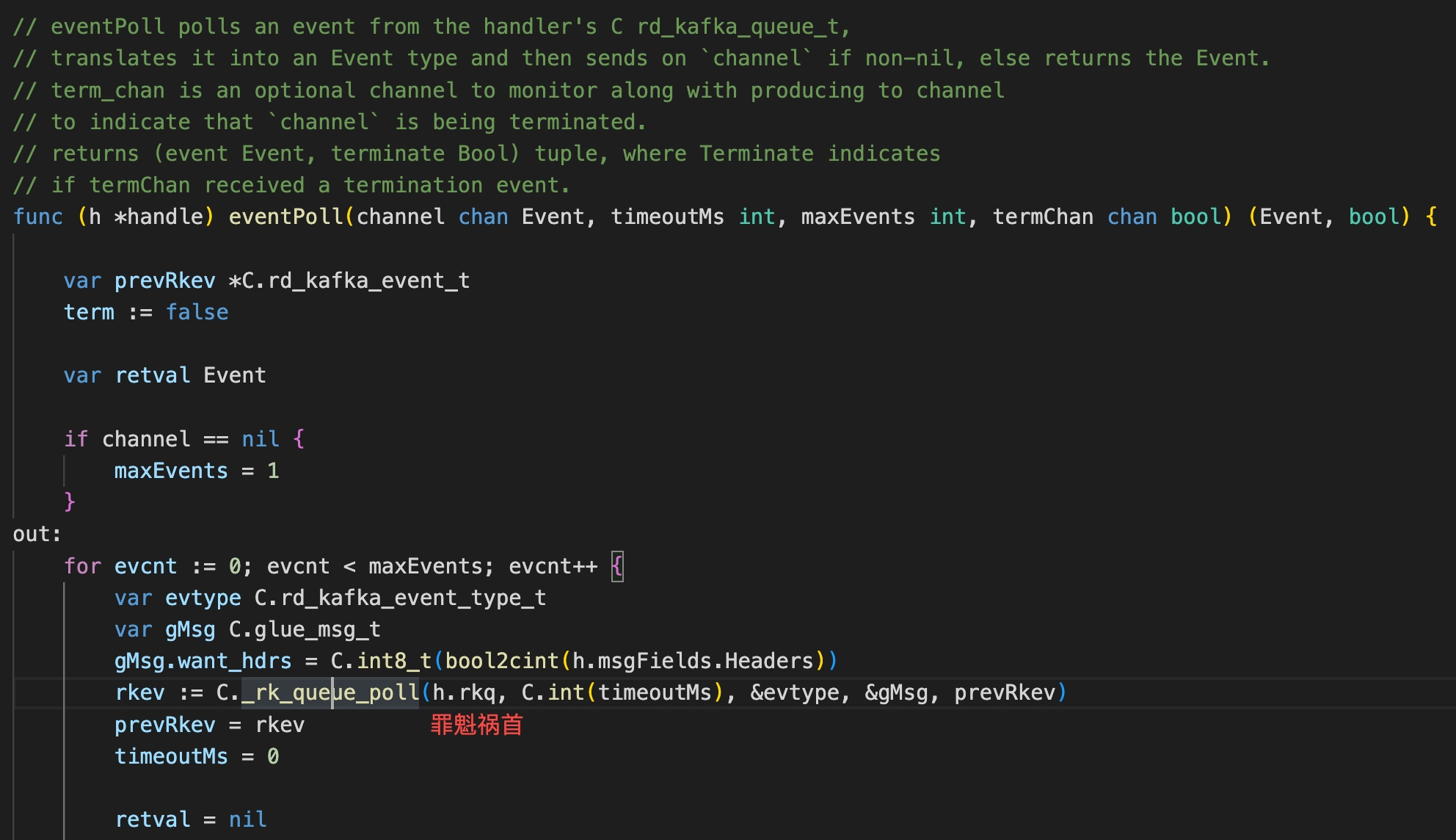
想到之前 confluent 给我留下的奇奇怪怪的印象 (主要是因为黑盒问题),再加上对 sarama 做过比较仔细的源码阅读,想着既然 confluent 不好调试,换成 sarama 先试试吧……
切换 sarama 后的压测
并发 200, qps 940
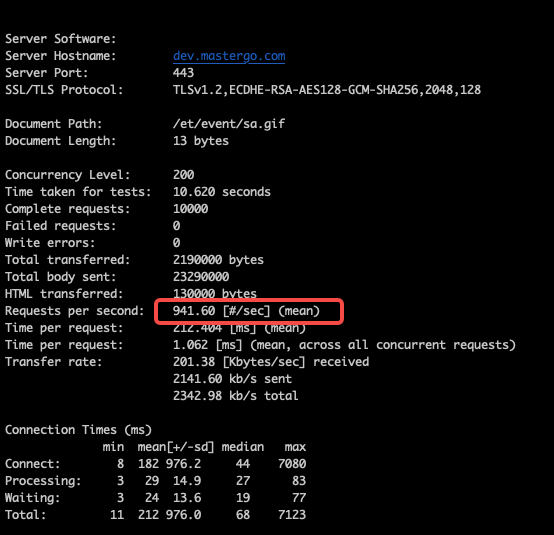
grafana 监控
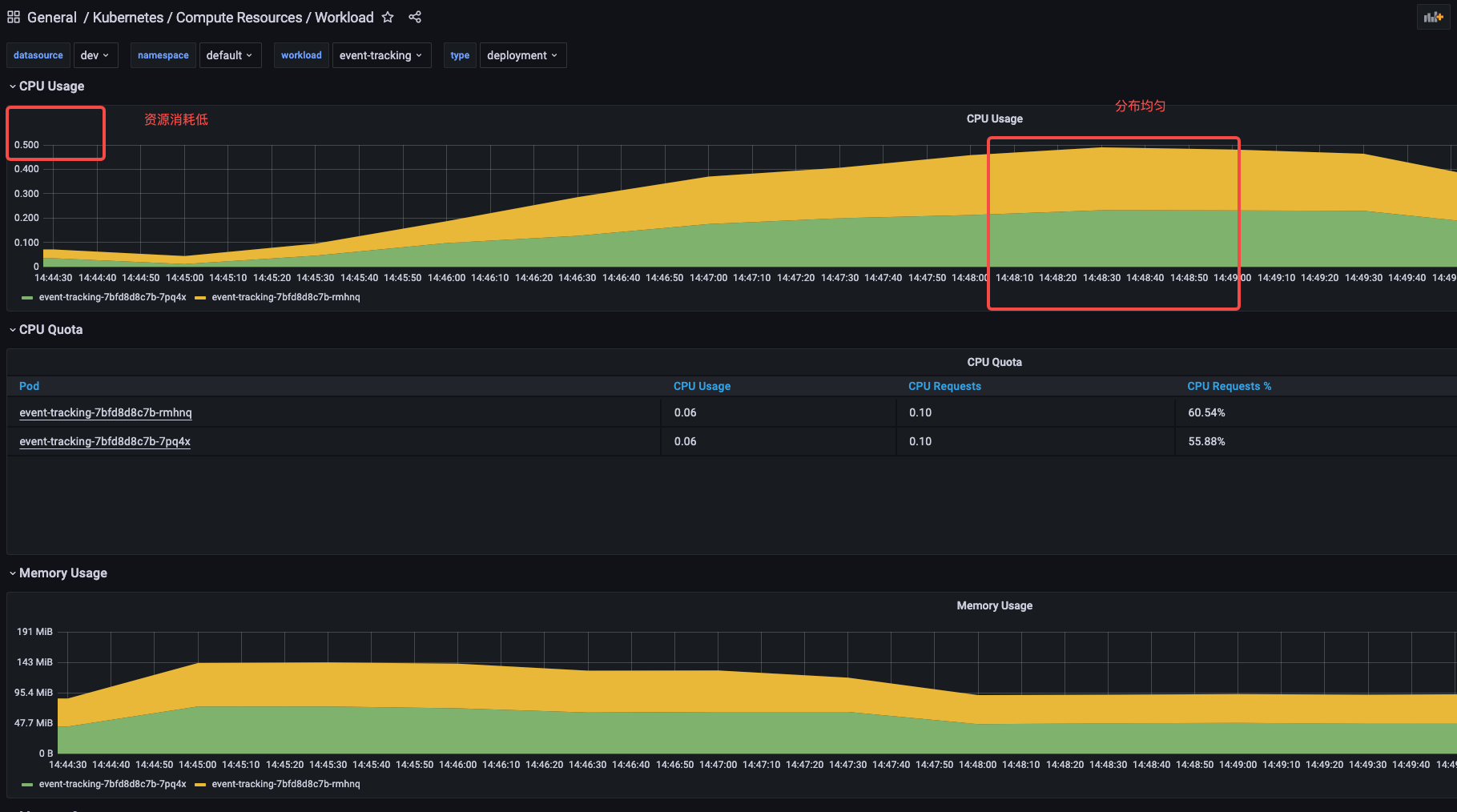
时间分布合理

打完 收工 !
结局:
Event-tracking 的性能问题至少算是解了
如果需要的话,可以再去整理下 confluent 的正确打开方式 ( 还是算了…… ,直接用 sarama 或者 kafka-go 不香吗 )
公共包最好还是提供一些统一的 metrics 接口、提供统一的 tracing 设置
对于我们现在大多数的业务场景,1c 的 cpu 支撑个 1000qps 问题是不大的,大家可能需要更新下对性能的感性认识
There are two kinds of failures: those who thought and never did, and those who did and never thought.
— Laurence J. Peter
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!