记一次扒 nginx ingress 的过程
背景
最近因为 nginx 网关的问题,导致服务有诸多不稳定的风险,因此需要更近一步去做网关的工作。
之前预判过将来会因无法自定义负载均衡而达不到目标,于是探索过 nginx-ingress 增加自定义负载均衡的方案,详情参见 记一次有状态服务的负载均衡方案探索 ,但由于当时业务还没有真正遇到问题,所以也没继续去推这个事儿。
不过当时的探索比较粗浅,是抱着 能简单解决问题 的目的做的,现在,需要有更多的梳理,以降低大家对这件事的认知复杂度。
nginx ingress
在 k8s 中,我们有多种提供对外访问的方式,其中业务中用的最多的,就是 ingress controller。 市面上提供的各类 ingress controller 非常多,例如 envoy、treafik、apisix、openresty 等等,我们选用的,是运维同学都比较熟悉的 nginx-ingress-controller。
nginx 的官网参考 nginx.org
nginx ingress controller 的官网参考 ingress-nginx , github ingress-nginx
先看一下 nginx ingress controller 的工作原理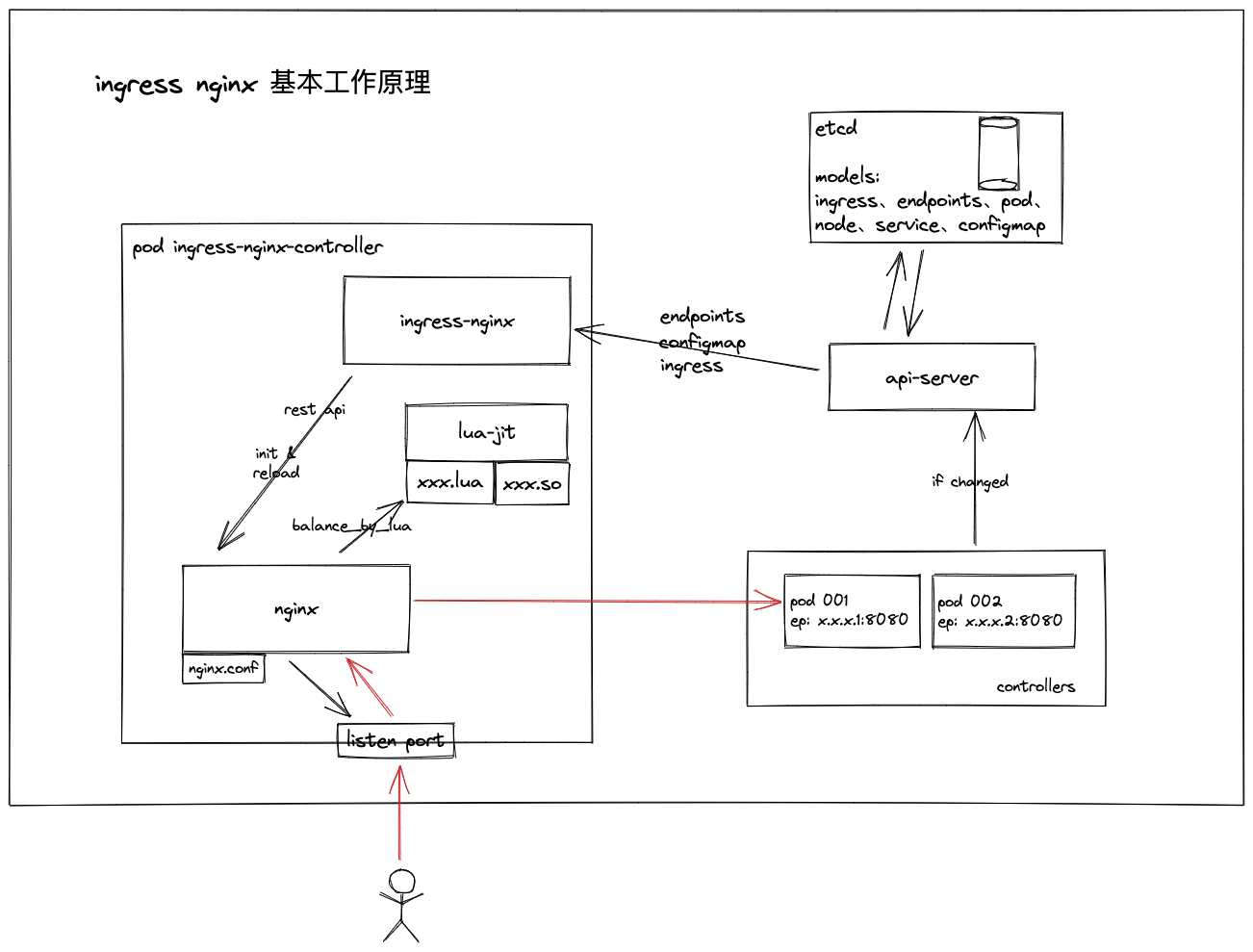
在这个过程中,ingress-nginx 的职责是 接收 api-server 中的资源变化,并转化成 nginx 需要的格式,通过 http 发送给 nginx
nginx
nginx 依然是我们熟悉的那个 nginx,但是和传统我们使用的方式不同,所有资源变化的处理,全都是交给 xxx_by_lua ,包括我们本次最需要被扒的 balancer 。
balancer 的入口文件是 lua/balancer.lua ,可以看到有这样的内容:
1 | |
其核心作用,就是做 balancer 的注册及获取。
我们用的是 chash 的方式,对应的代码在 lua/balancer/chash.lua ,内容如下:
1 | |
其实这里面什么都没做,就是封装了一下 resty.chash ,继续扒一下这个库的源码 openresty/lua-resty-balancer/lib/resty/chash.lua,内容如下:
1 | |
可以看到,这个文件实现了 find 的方法,而底层 hash 环维护的事交给了 librestychash 这个 clib,继续看一下 openresty/lua-resty-balancer/chash.c,代码如下:
1 | |
这就是 chash 本身的实现了,比较简单,主要的结构如下
1 | |
这是一个 point,理解成是 hash 环上的每一个桩就行了,整个 hash 环使用数组来实现。
我们遇到的问题
背景场景
使用的 ingress-nginx 做应用网关,应用中有一个 websocket 的服务,会有大量的连接保持着。 同时,为了让缓存发挥作用,我们使用了 nginx consistent hash 的方式让同一个 room 下的连接在同一个 pod 上。
存在隐患的场景有如下 2 个:
当 ingress 发生变化,ingress-nginx会在一段时间后强制停止 worker 进程。这会导致短时间内大量 websocket 重新连接,无异于一次攻击 🐶 ……
当服务进行更新部署时,若采用大批量更新,则会导致短时间大量重连,和场景 1 有异曲同工之效;若采用小批量滚动更新,则会导致部分用户会进行多次重连。
可能的思路
能否让 hash 环不发生变化?
从 nginx-ingress/lua/chash.lua 中可以看到,hash 环生成的方式是以 endpoints 为基准的,如果 endpoints 不发生改变,则 hash 环不会发生改变。
1 | |
ep 是每一个 pod 的 ip,会随着 pod 的更新而更新,所以答案几乎是否定的。(当然还是有一些奇怪的操作可以达到目标,但不常规操作还是少搞的好,不然就是大坑一个)
能否让负载均衡可控?
嗯,这个自然是可以的,基本 demo 可以查看 记一次有状态服务的负载均衡方案探索
当然,为了让整套体系能够起作用,还需要做大量的体系性工作,之前有一个简单的 demo,可以查看 用 operator 做点有趣的事
这里可以更细致地做一些原型出来
能不能让网关重启不会导致连接断掉?
按照调研,目前市面上能看到 mosn 是做了连接平滑迁移的,这里去看一下,它具体是怎么做到的,有什么优劣?
mosn 的代码地址: https://github.com/mosn/mosn
一篇关于 mosn 是怎么做的迁移: nginx vs envoy vs mosn 平滑升级原理
基本结论是: mosn 和 envoy 都使用了 UDS (unix domain sockets) 的技术,这是在 linux 内核 3.5+ 支持的一种文件描述符传递的方案。
追了一下 mosn 的代码,核心逻辑如下:
1 | |
关于具体细节的问题,可以再细致看一下代码,或者调试一下。
关于转移连接描述符的操作,代码如下:
1 | |
这里可以画一下流程图,可能更好理解一些。
能否使用 UDS 解决业务升级问题?
实现上当然是 ok 的,但不建议这么搞,主要有以下原因:
- 业务不是网关,代码的稳定性是很不好的,需要经常变更,为了满足隐藏的一些需求,还是在业务层做特定机制的建设更好。
- 我们的服务都运行在容器中,对 k8s 而言,镜像是不可变的,平滑升级导致我们在不可变的镜像中使用了可变的进程,容易出问题。
我们究竟要解决什么问题?
- 让大规模重连尽量不要发生
- 网关独立,不被其他对网关的改动而影响
- 使用能平滑迁移的网关,如 mosn
- 业务应用平滑启动
- 少量 pod 滚动更新
- 坏处: 部分连接会多次重连(这里涉及 ws 服务目前均衡的具体实现,需要再细看代码) ;
- 好处: 对数据库的压力较小 ;
- 要解决的问题: ws 服务本身会不会被突然重连的压力搞出问题 => 加多一些 vnode
- 蓝绿发布、连接迁移
- 少量 pod 滚动更新
- 让大规模重连也不会引发重大问题
- session 机制 (这个我觉得还是很有效的)
- 考虑用 redis、甚至内存 的方式做连接信息管理
- 限流降级熔断机制
- 网关层限流等
- 业务层限流等
- 前端自身限流等 (至少不要疯狂重连吧 😂 )
- 其他可能的问题
- 再细致地查一查,经常断掉是怎么发生的,会不会是心跳机制的问题
- 内存泄漏和协程泄漏往往是同时发生的,是不是可以把协程池弄上,然后监控起来
- 前端的策略还是有很多可讨论的,比如 长期在后台的页面,是不是把连接断了不要连了
- 多个连接的价值需不需要再探讨一下? (不一定,紧要性不高)
- 每天晚上的几千个连接还是有点问题的,查一查心里稳妥些
实际上,我们可能主要的问题还是 mongodb 索引少建了一个,在此基础上或许一切的问题都是可以堆一点资源就解决的 🐶 ……
业务有时候就是这样,解决问题或许比牛逼的技术有更大业务价值……
其他
- openresty 库中还有很多实用的工具,之后有机会可以详细扒一下,例如:
1 | |
另一个常用的负载方式是 chashsubset ,实现在 chashsubset.lua ,后续可以继续扒一下
mosn 的实现中还有很多可以参考的地方,比如 wasm 的扩展方式、xprotocal 的扩展方式,看看还是有价值的
Anticipate the difficult by managing the easy.
— Laozi
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!