alertmanager等监控项目源码走读
背景
最近在做私有部署的监控告警方案,由于我们线上用的是 promethues + alert manager + grafana 的方案,为了保持方案一致性,也使用了这套方案。
但在梳理需求的过程中,发现了一些其他的应用,具体可以查看:
其中,发现 easeprobe 和 checkup 这两个项目还挺有意思,这和我们平常所认识的: promethues 、 zabbix、open-falcon、Nagios、datadog 等等不同。 这两个项目都是面向简单环境下的检查,很轻量,都是一个配置文件 + 一个二进制文件 即可运行起来。
在这里对 alertmanager 、easeprobe 、 checkup 做一次源码走读,看看有些什么可以借鉴的。
整体认识
对于监控告警而言,整体来说有这么几个核心概念:
- 监控探测
- 探测数据存储
- 数据检查规则
- 告警分发
- 告警组
- 告警渠道
- 辅助系统
- api server
- fontend admin page
以上是一个监控告警系统的核心环节,当然,在这之上可以添加很多辅助系统,例如用户系统、权限系统 等等。
代码走读
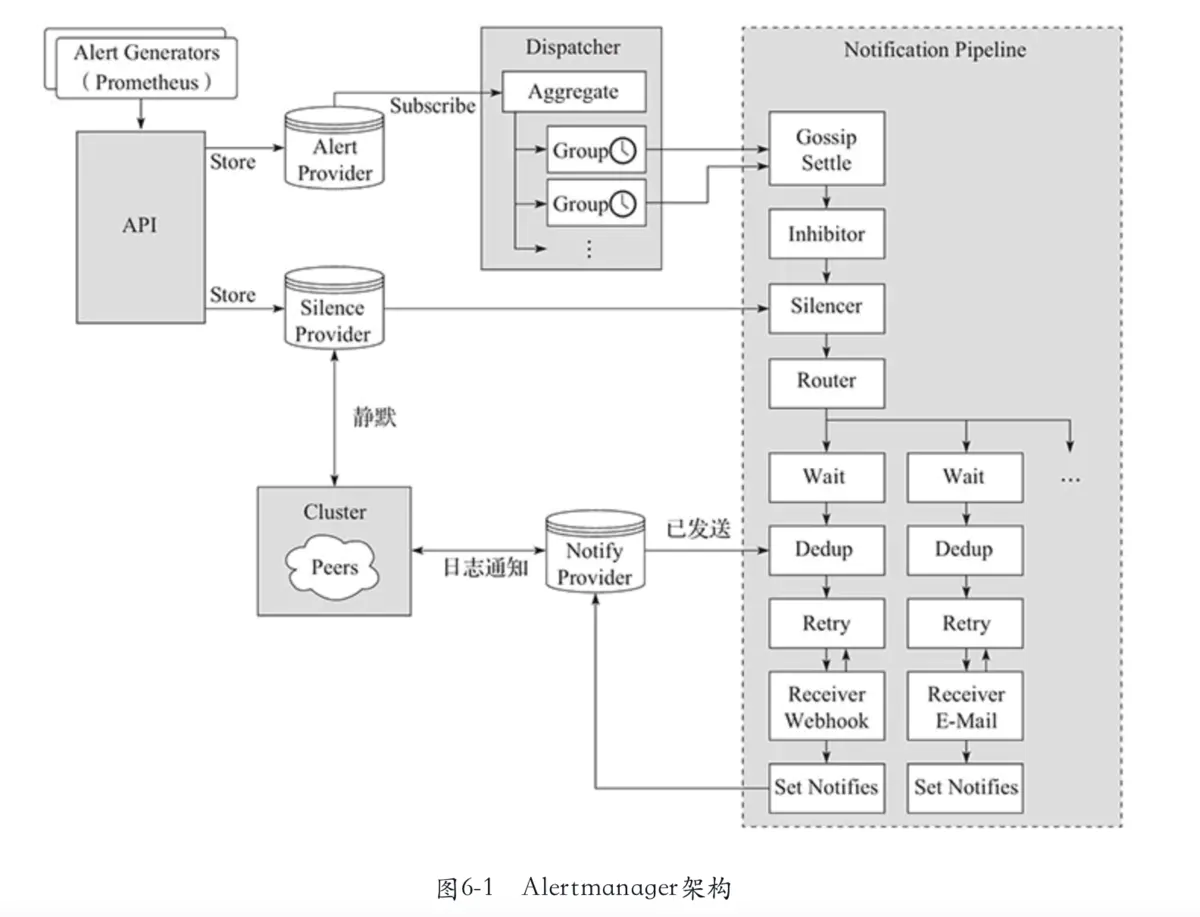
alertmanager
代码层级主体职能
cmd
- amtool
- 这是 cli 的入口文件,详情可查看 cli 目录
- alertmanager
- 这是 server 的直接入口文件
- 做一系列的初始化,例如: nflog(详见 nflog 目录)、cluster (详见 cluster 目录)、slience (详见 slience 目录)、mem provider (详见 provider 目录)、dispatch、api server (详见 api 目录)
- amtool
config
- 配置的 model,主要有 route (分发路由)、notifier (通知渠道)
dispatch
- 实现了 route 和分发逻辑。两个循环,① 循环接收 alerts ② 对每一个 alert 循环判断是否需要分发到 route。
- 聚合了 route(aggrGroup)、provider.Alerts、notify.Stage 等实例。
api
- api server 的实现
- restapi : 做了一个 http server 的封装,我们一般使用现成的框架,例如 gin、echo 等等。
- api: 具体业务接口的实现。
- operations: 做了一些 params 和 response 的定义,看起来感觉实际意义不大。
- models : 接口的模型,做了 Validate 和 marshal 的逻辑,我们一般使用 tag 的方式做 validate,使用 http 框架提供的 bind 等做 marshal 操作。
- client: 实际的 service 接口,业务方可直接使用作为 client sdk。
notify
- 通知的具体实现,有很多通知类型,写一些通知工具的时候可以参考: email、discord、opsgenie、pushover、slack、sns、telegram、webex、wechat……
- 扩展很方便,仅需要实现 Notify 接口即可。
provider
- alerts 的暂存和分发,目前仅有 mem 的实现。
store
- 存储的实际实现,主体为一个 map 结构,有 gc。 provider 的 mem 中存的也是这个。
silence
- 静默的实现
types
- 几个公共的 model
cluster
- 集群实现
cli
- 提供一系列 cli 命令,主要是用于和 server 交互的,例如 添加告警、添加静默、获取状态 等等。
- 使用的 alecthomas/kingpin cli 框架,我们平常用的是 cobra。
timeinterval
- 自己实现了一个时间周期判断器
asset
- 用的 github.com/shurcooL/httpfs 把静态资源打包到二进制文件中,保证了启动服务的简单。
nflog
- 每隔一段时间把接收到的 notify 情况进行 log 存储,用 proto 定义了 entry,存的也是 protocal buffer。
ui
- 管理面板的实现,前端项目,最后会打包到 assets 中。这种模式很方便,可以参考。
把 proto 作为 model 使用
- cluster
- nflog
- slience
使用二进制文件存数据
- nflog
在网上看到这个,觉得不错
easeprobe
- channel : 消息通道,用来绑定探测和通知的
- cmd : 服务的入口,做配置解析、绑定探测器、绑定通知 等等
- conf : 全局的配置定义
- daemon : 做 pidfile 管理,避免重复启动,没有重启能力
- eval : 结果解析器,有 JSON、xml、text、html 等解析器,可以定义更丰富的结果判断方法
- global : 定义一些全局变量
- metric : 对接 promethues 指标
- notify : 消息通知渠道,有很多种通知,可以参考
- base : 所有 notify 公共的字段和方法,继承 和 实现接口 是两种很通用的多态方式。
- probe : 探针的逻辑,最核心的部分
- data : 使用全局变量,保存所有探针结果。 status 为探针得出的结论。stat 为每次探测的记录。result 为当前探针的结果,包括了 status 和 stat 以及 探针本身的信息。
- base : 探针的主题逻辑,使用 Config(probeFuc) 的方式实现多态,由各种探测方式自行进行探测,并返回结果给 base。
- report : 拼接各种报告模板
- web : 提供 metrics 采集 和 报告获取接口
整个服务实现得很简单清晰,很值得参考,主要有 ① 全局 config 的定义 ② 探针和 notify 的多态实现。
checkup
- check : 提供了一些检查方式,有 http、tcp、tls、dns,还有 exec
- cmd : 命令的入口文件
- 采用了 cobra 的命令行框架
- 提供了几种执行探测的方式
- serve : 提供了 web 服务,具体的前端代码在 statuspage 中
- notifier : 几种通知的方式
- 每次检测 (每次检测可配置多次测试),如果有错误就进行通知
- storage : 提供了多种存储方式,可用文件存储,也可用 sql 存储
- types : 一些 model 的定义
- checkup.go、notifier.go、storage.go 都是一些 model 的定义
这个工具非常简单,把几个部分都拆得特别干净,相互没有依赖,也没有全局依赖,和上面两个不同的是,它完全采用了 无状态 设计,这让它可以实现分布式部署,所有数据都汇总到一个独立的地方,再对数据做聚合。
吐槽一下,界面还是有点…… 🤦🏻♀️
简单思考
这几个项目都比较简单,在梳理清楚 工具的目标 之后,实施起来实际上都不会特别麻烦。
但不同的开发者,看问题的视角和开发习惯都不完全相同,因此也有一些编程技巧是可以借鉴和学习的。
你想得到什么?
这些都只是工具而已,看过了一遍代码也就过去了,关键还是得知道: 你究竟想得到什么?是否有战略目标?是否能把自己看到的这些东西融入到自己的一套体系中?
我希望得到:
- 企业级业务系统可直接使用的监控方案
- 小项目可直接使用的监控方案
后续 TODO
走读 pushgateway 代码prometheus代码走读走读 prometheus 代码prometheus代码走读走读 prometheus client go 代码(简单看了下,没什么特别说的)完全走一次 promethues 的监控告警流程简单的集群监控方案- 梳理在具体业务中使用 easeprobe 的场景
- 考虑家用场景
- 考虑看板 和 ui 平台的价值
This is the final test of a gentleman: his respect for those who can be of no possible value to him.
— William Lyon Phelps
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!